|
Getting your Trinity Audio player ready...
|
There are numerous technical articles available on querying data with AI, yet non-technical articles on this topic are scarce. Here, we’ll give a non-technical overview of Retrieval-augmented generation (RAG), a technique for enhancing the accuracy and reliability of AI models with facts fetched from external sources.
1. Preparing your data
The first step in querying your own data is to prepare it. There are 3 keys steps to this:
- Identify relevant data
- This involves reviewing your available data sources and determining which parts contain the information most relevant to your needs. Consider the type of questions you want to answer or the tasks you want to accomplish, and select the data that is most likely to be helpful.
- Extract the data
- This may involve filtering, sorting, or otherwise processing the raw data to isolate the relevant fields, records, or documents. The goal is to create a focused dataset that contains only the data that will be used by the model.
- Clean the data
- Remove any unwanted or unnecessary data
- Address missing values or inconsistencies
- Ensuring the data is in a format that can be easily ingested by the RAG model
2. Store your data
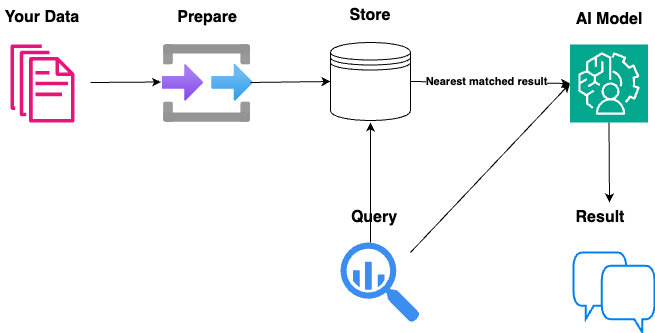
Once prepared your data needs to be stored. This involves breaking your data down into smaller pieces (called “chunking”) in order to store it in a more efficient and meaningful way. There are a few strategies you can choose at this point depending on the type of data you’re storing. For example, you can break it down by paragraph, by character count, by semantic meaning or one of the other available methods.
A good chunking strategy is key to getting relevant and meaningful results from your data. Short chunks will preserve meaning but lack context while long chunks will tend to smooth out nuances of each sentence.
Now you’ve broken your data down into smaller chunks you can store it. A common method of storing your chunked data is to use a vector database. A vector database is like a specialized library that stores and organizes information in a way that makes it easy to find and retrieve similar items quickly. It’s used to handle complex data, like text or images, by turning them into numerical codes that capture their main features. This makes it possible to search for items that are similar to what you’re looking for by finding the nearest match to your given query.
3. Retrieve your data
Your now ready to retrieve the results based on the given query. It’s important to note here that you’re not querying the AI model, you’re querying your vector database from Step 2 above to find the best results. When you search, the database looks for the numerical codes that are closest to what you’re looking for. This allows it to quickly find the results that are the most similar or “nearest” to your search, even if they don’t exactly match what you typed. The database can then show you the top matches, giving you the most relevant information without having to sift through irrelevant results.
4. Generate a response
You then pass both these top matches returned from Step 3 and the original query to the AI model which will generate the response to the user. This is the Generation part of RAG. This “Generation” part of RAG allows the large language model to take the relevant information retrieved from external data sources and use it to generate a more accurate, contextual, and up-to-date response to the user’s query.